Another day in perf
Sometimes you hear people say stuff like "premature optimization is the root of all evil." They're right, even beyond the letter of the words. But there is a certain amount of evil that we must accept.
Recently I was digging through some of the oldest service code still in use at my day job. I needed to reuse it in a different context. It's a connection code for redis.
It's my old code, so I expected to be able to reuse it pretty easily. But reading it carefully I remembered one of the changes I made forever ago was to change the connection pool implementation. Previously, there was this bug in rust's redis library where you could misalign your requests and responses. That's about the worst thing you could imagine happening for a multitenant service. So I changed the pool. But I didn't change the way I integrated my code with the pool...
Situation
What I had made worked fine for years. Our daily benchmark measures 1 small instance's latency at lower rates, and throughput at the top end of the test. The test was topping out at 82khz, and p99's at 9ms at 70khz. That's not bad, so why go looking for more performance?
Well, I was not looking for more performance. I just noticed that this code uses a mutex to manage a connection. This old strategy also funnels all requests into 1 domain socket connection.
I remembered that connection type changed from the original code. Originally, you had to have a mutex. But this new connection type didn't strictly need that.
So I did 2 things: First, I removed the mutex. That forced me to pull connection establishment out of the lazy path into the startup path. That meant bleeding an async frame up the stack to all test setup and consuming applications. While I did that I realized that there was no need to limit to 1 connection. So second, I added a startup configuration to set the pool size. Load across the pool of sockets was balanced by a round-robin atomic integer.
So I reimagined the startup code to eagerly make the connections, hooked up the configuration, plumbed the updates to the test setup code, and shipped the change.
Result: 3 hours for 4.8%
The morning after shipping, I checked the daily load test results. Prepare to be underwhelmed:
| requests per second | latency | |
|---|---|---|
| before | 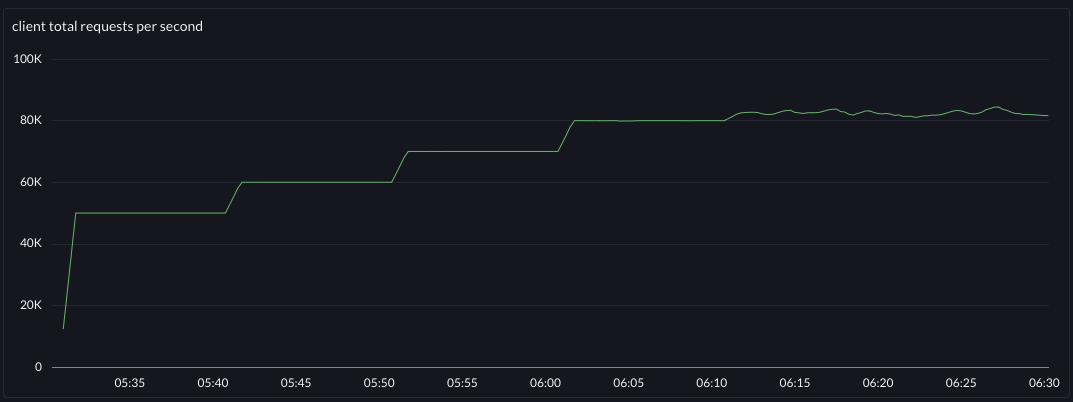 | 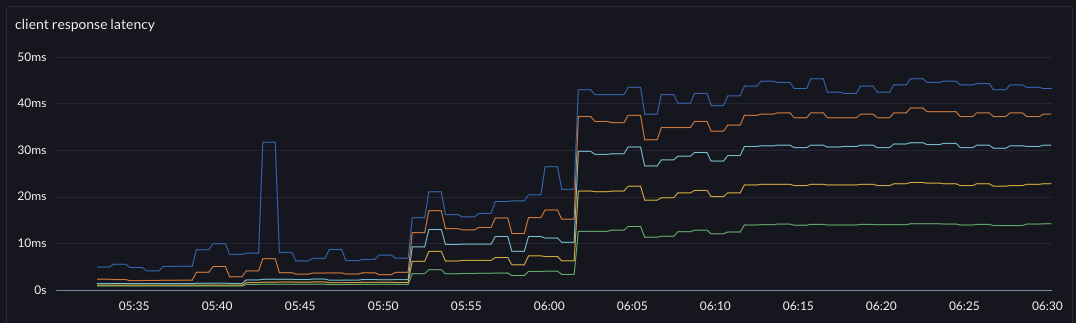 |
| after | 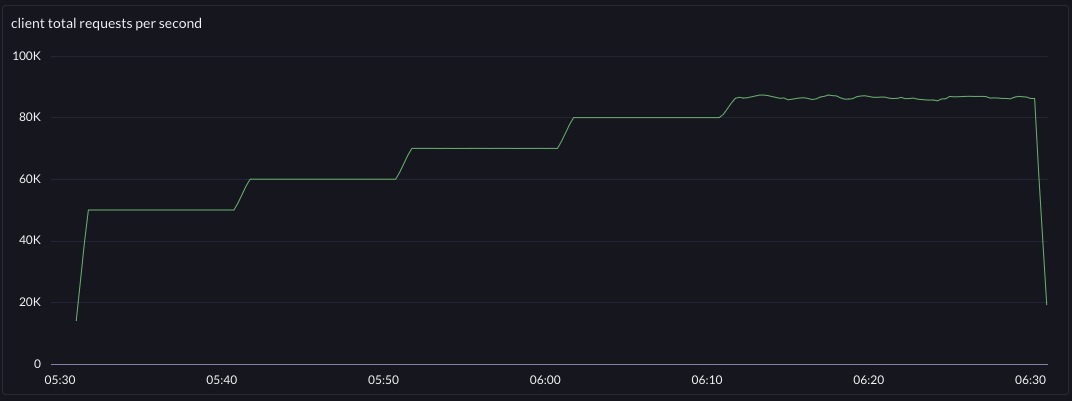 | 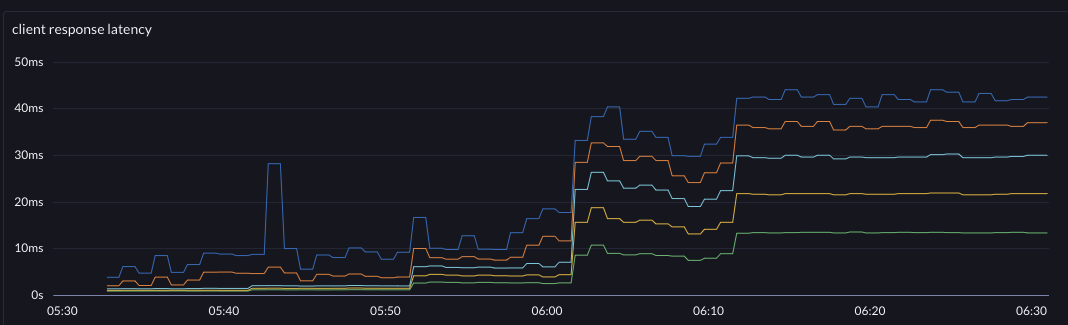 |
The change improved system throughput by around 4.8% and pulled down the p999 at 70khz by 38%. Furthermore, the system now has an 80khz "step" where before that was basically the edge of instability (at the test's fixed connection limit).
@70khz
p999 13ms -> 8ms
p99 9ms -> 6ms
p90 6ms -> 4ms
p50 3.5ms -> 2.5msSo this accidental change that took about 3 hours to read, remember, fix, deploy, and observe brought about 4.8% more throughput per server, end-to-end in this tuned system. It was a premature optimization - nobody was asking for it. But it was tech debt, and simplifying was the root cause of the improvement. You be the judge of whether this premature optimization and simplification was worthy or just evil.