The story of yet another rpc framework
Sometimes you have to write something new that does what you need. I have had to do a few of those exercises recently. In all honesty, even in a vacuum I prefer a system that does exactly what it is meant to do; so I am not sad to have made a new framework that tries to let you do whatever you need to.
At Momento, I started us off in 2021 with kotlin coroutines and grpc. That worked for a year, but we outgrew kotlin. Too much time tuning the garbage collector for one benchmark, only to regress another. That's a story for another time though. In late 2023 I saw that we had outgrown grpc, and in 2024 I replaced our interserver communication with Protosocket.
Grpc is a fine technology, and it's good enough for just about anything. The issues we had with it were a combination of factors from grpc's design, rust's ecosystem, and Momento's need for microsecond-level optimizations.
Grpc design: Grpc is built on HTTP. So each request carries headers, is routed, and is authorized separately. There's a whole context built up for each rpc. If you have lightweight rpcs, the context and framework takes up nearly all of the cpu cycles actually spent on servicing the rpc. That was the situation we were in.
Rust ecosystem: In the tokio world, hyper is the most standard http framework. It wraps h2, which is the most standard rust http2 implementation. If you want to use the standard tools, you use tonic which opts you into that whole stack. Anyway, h2 has a long-standing issue with the way they manage buffers across concurrent http2 streams. They use a std::sync::Mutex several times per stream. When you use this in a tokio web server, you get whole-runtime parks for a few hundred microseconds to a few milliseconds at a time when request handler threads try to complete around the same time. This caused us no end of pain.
Microsecond-level optimizations: Momento was building a cache router. In an ideal world, you would not need a router. So in an ideal world, the router should approach zero cost. You just can't park your rpc handler threads while there is work to do. This was bigger than a microseconds-scale optimization, which by itself would have been enough to motivate integrating this.
When Redis went closed-source, before Valkey really became a thing, I was annoyed with Redis. I figured it left too much on the table in terms of performance as well as data types. So I made some rmemstore project, and found that I liked the way I did the rpc channel. I extracted it into its own library and thus protosocket was born.
What is a protosocket
A protosocket is a non-blocking, bidirectional, message-streaming connection over TCP. No other wrappers are layered. No http, grpc, websocket framing, no hyper, axum, tonic. You supply messages and a codec, something like protocol buffers or messagepack, whatever you like. Protosocket streams your messages to and from the other end. Optionally you can use the protosocket-rpc machinery if you want to do rpc's instead of arbitrary messaging.
This is a level between complex socket programming & high level http. Protosocket is for moving messages between two servers you control as cheaply as the kernel will allow. If you want to spend your CPU on your work instead of on the framework, you might want to think about protosocket.
The core type is the Connection. A Connection is a Future. You spawn it, and it owns one socket for its entire life. So protosocket is a connection-aware framework, and you can do what you want with that. For example, you can authenticate once, and reuse an auth context for subsequent calls.
An event loop per connection
Every time a Connection is polled, it does four things, in specific order:
readthe socket into a receive buffer- decode inbound messages and hand each to your
MessageReactor(orConnectionServerif using rpc) - poll the
MessageReactor(again, or yourConnectionServer) to push its state forward - dequeue outbound messages, encode them, and
writevthem
There are no locks. One Future (a task) owns the socket, the read buffer, the write buffer, and the codec. When a message arrives, it can be answered in that same poll, before the loop ever yields.
Since it's a Future, the loop is able to give &mut self to the trait functions you get to implement. That means you can use Vec<Whatever> instead of Mutex<Vec<Whatever>> and just unconditionally do what you need to.
The protosocket trick to keeping latency low is in the ordering of operations in the Connection, as well as working with rust's Future type strengths to give you all the statically typed mutable safety that rust has to offer. I made protosocket to get out of the way and give you tools, more than to impose a way you have to do things.
The reactor, a pleasing symmetry
From the Connection's perspective, your code goes into a MessageReactor. It's a small trait:
pub trait MessageReactor: 'static {
type Inbound;
type Outbound;
type LogicalOutbound;
/// a message arrived off the wire
fn on_inbound_message(&mut self, message: Self::Inbound) -> ReactorStatus;
/// a message is on its way out
fn on_outbound_message(&mut self, message: Self::LogicalOutbound) -> Self::Outbound;
// (and an optional poll() to drive your own state forward)
}You get &mut self, and you get your messages by value. You can do anything you need to in here. For example, protosocket-rpc spawns a task for the message and wraps it with a future that sends the result back to the outbound channel.
Reactors are primarily inbound message reactors.
A client and a server are the same Connection. You use a different MessageReactor of course, because servers do different things than clients. But the core Connection is exactly the same thing.

On the client, the usual reactor is an RpcCompletionReactor. When you send a request, on_outbound_message retains a completion - a oneshot for a unary call, a stream for a streaming one - in a registry keyed by message id. When the response comes back, on_inbound_message looks up the id and completes the future you're awaiting. Drop the future before it resolves and the client quietly sends a cancellation upstream.
On the server, the usual reactor is an RpcSubmitter. on_inbound_message takes the request and calls new_rpc(message, responder) on your service, which spawns the work (or just does it, I mean it's your code so do what you want). As your handler produces responses, they flow back out through on_outbound_message.
It's the same Connection loop, calling the same trait. The client matches responses to waiting requests; the server matches requests to handlers. It's a mirrored implementation across inbound and outbound concerns.
A bottleneck - channels
The Connection is a single task that owns the socket. But the outbound messages come from anywhere. Any task on any thread that wants to can send messages. How do all those producers get their messages to the one consumer?
I mean, per usual, a channel. That's shouldn't surprise, and to make matters even less interesting, I reached for the standard one, tokio::sync::mpsc. It worked, and is lock-free. But also, for this particular shape of problem, it is slow.
I went looking in flamegraphs for any protosocket backpressure and observed the Connection spinning in the tokio mpsc lock-free OCC code. Many producers and one consumer running as hot as it can is a worst case for a lot of lock-free MPSC designs. Every producer vies for the same atomics, and the clever cross-sender ordering machinery isn't free. Ultimately, these channels are lock-free, pedantically speaking, but they are never synchronization-free.
So I wrote spillway mpsc. It is aggressively boring. It's basically a Vec<Mutex<VecDeque<T>>>.

Each Sender is bound to a lane when it's created. When it sends, it locks its lane. Two senders on different lanes never touch the same mutex, so they never wait on each other. I also support sending batches of messages, so users can pretty much send unlimited message rates through spillway.
The Receiver takes messages a whole buffer at a time, which keeps producer/consumer contention low. As delivery rate increases, so too does the efficiency of the consumption...
When Receiver wants to receive, it finds a lane with messages, swaps that lane's whole VecDeque out for its own empty one in a single locked moment, and then drains the queue with no lock. There's no unsafe or clever lock-free spin loop. On my old M1 tokio's mpsc does about 4.5mhz while spillway does about 92mhz at a fraction of the latency and jitter. It's better than a 20x throughput increase.
The cost is that you only get message ordering per-sender. You don't get it globally across senders. That's enough of a guarantee I'd argue for nearly every mpsc user.
It's stupid and simple, but it's fast and safe 😃
What it did
The point of this wasn't an optimization, but more of a transformation. Iterative improvement wasn't enough for the applied use case I had. But changing rpc frameworks is a big lift, so it needed to have a big benefit.
Optimizing the existing framework wasn't pointless. I wrote k-lock, a drop-in std::sync::Mutex replacement tuned for tokio servers. It spins harder and wakes more eagerly, because a parked runtime thread costs hundreds of microseconds to revive. I forked h2, swapped its mutex imports for k-lock, and got about 20% more throughput. To quote Lamar, it's not enough.
Changing the rpc approach was next. Pulling protosocket into the service improved its effective vertical scale by about 2.75x on the first integration. That's a good optimization, and worthwhile. It was transformative for how we approached performance.
A couple before (grpc) and afters (protosocket), presented without comment:
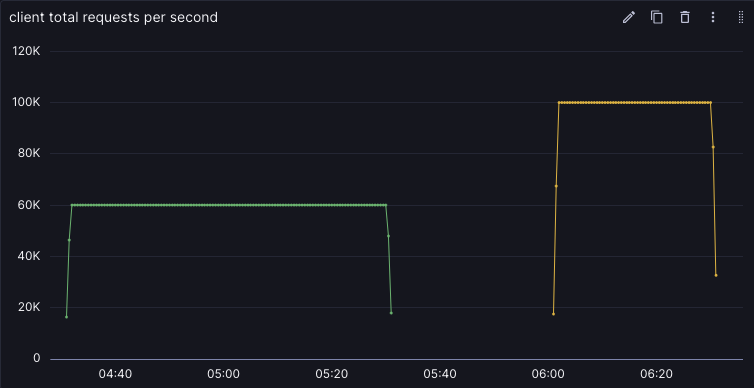
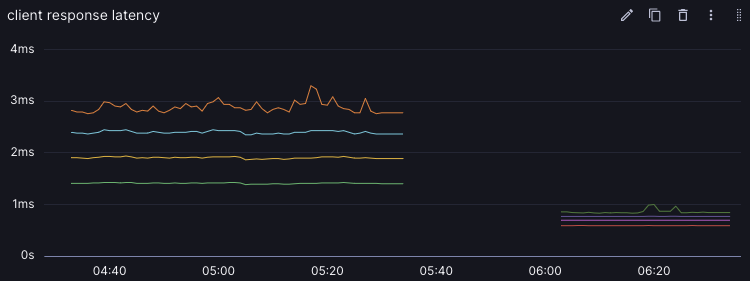
Per EC2 dollar, for small RPCs, protosocket after the v1 release is over 10x better than the grpc setup it replaced.
So should you use it?
Probably not, honestly. Grpc is fine. It's good enough for almost everything, and it does a lot of things outside of protosocket's domain. If you don't own both ends of the wire, or you can't measure your framework spending more cycles than your actual work, reach for the boring, well-supported thing.
But if you have measured that, and you do own both ends, there is an enormous amount of headroom underneath HTTP. Protosocket is what I put down there: One connection, one event loop, one task per stream, a reactor for your logic, and a fast channel feeding it.
There's no magic in protosocket: There's just less in the way.
2026-06-16